RAG Q&A over Documentation
The code for this tutorial is available here.
In this tutorial, we'll build a Q&A system for our documentation using RAG (Retrieval-Augmented Generation). Our AI assistant will answer user queries by retrieving relevant sections from our documentation and using them as context when calling an LLM.
At the end, we will have:
- A playground for testing different embeddings, adjusting top_k values (number of context chunks to include), and experimenting with various prompts and models
- LLM-as-a-judge and RAG context relevancy evaluations for our Q&A application
- Observability with Agenta to debug and monitor our application
- A deployment that we can either directly invoke or fetch the configuration to run elsewhere
You can try our playground by creating a free account at https://cloud.agenta.ai and opening the demo.
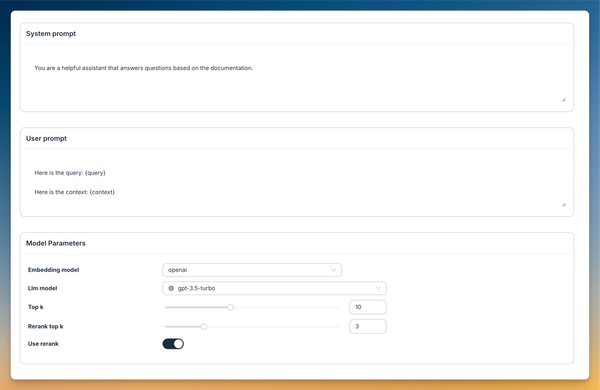
Our stack
- Agenta for playground, evaluation, observability, and deployment.
- LiteLLM for interacting with language models and embeddings.
- Qdrant as our vector database for storing and querying document embeddings.
Ingestion pipeline
The first step is to process our documentation and store it in a vector database for retrieval. Let's start by looking at how we ingest our documentation into Qdrant.
OPENAI_EMBEDDING_DIM = 1536 # For text-embedding-ada-002
COHERE_EMBEDDING_DIM = 1024 # For embed-english-v3.0
qdrant_client = QdrantClient(
url=os.getenv("QDRANT_URL"), api_key=os.getenv("QDRANT_API_KEY")
)
def chunk_text(text: str, max_chunk_size: int = 1500) -> List[str]:
"""
Split text into chunks based on paragraphs and size.
Tries to maintain context by keeping paragraphs together when possible.
"""
# Split by double newlines to preserve paragraph structure
paragraphs = [p.strip() for p in text.split("\n\n") if p.strip()]
chunks = []
current_chunk = []
current_size = 0
for paragraph in paragraphs:
paragraph_size = len(paragraph)
# If a single paragraph is too large, split it by sentences
if paragraph_size > max_chunk_size:
sentences = [s.strip() + "." for s in paragraph.split(".") if s.strip()]
for sentence in sentences:
if len(sentence) > max_chunk_size:
# If even a sentence is too long, split it by chunks
for i in range(0, len(sentence), max_chunk_size):
chunks.append(sentence[i : i + max_chunk_size])
elif current_size + len(sentence) > max_chunk_size:
# Start new chunk
chunks.append(" ".join(current_chunk))
current_chunk = [sentence]
current_size = len(sentence)
else:
current_chunk.append(sentence)
current_size += len(sentence)
# If adding this paragraph would exceed the limit, start a new chunk
elif current_size + paragraph_size > max_chunk_size:
chunks.append(" ".join(current_chunk))
current_chunk = [paragraph]
current_size = paragraph_size
else:
current_chunk.append(paragraph)
current_size += paragraph_size
# Add the last chunk if it exists
if current_chunk:
chunks.append(" ".join(current_chunk))
return chunks
def process_doc(file_path: str, docs_path: str, docs_base_url: str) -> List[Dict]:
"""Process a single document into chunks with metadata."""
with open(file_path, "r", encoding="utf-8") as f:
# Parse frontmatter and content
post = frontmatter.load(f)
content = post.content
# Calculate document hash
doc_hash = calculate_doc_hash(content)
# Get document URL
doc_url = get_doc_url(file_path, docs_path, docs_base_url)
# Create base metadata
metadata = {
"title": post.get("title", ""),
"url": doc_url,
"file_path": file_path,
"last_updated": datetime.utcnow().isoformat(),
"doc_hash": doc_hash,
}
# Chunk the content
chunks = chunk_text(content)
return [
{"content": chunk, "metadata": metadata, "doc_hash": doc_hash}
for chunk in chunks
]
def get_embeddings(text: str) -> Dict[str, List[float]]:
"""Get embeddings using both OpenAI and Cohere models via LiteLLM."""
# Get OpenAI embedding
openai_response = embedding(model="text-embedding-ada-002", input=[text])
openai_embedding = openai_response["data"][0]["embedding"]
# Get Cohere embedding
cohere_response = embedding(
model="cohere/embed-english-v3.0",
input=[text],
input_type="search_document", # Specific to Cohere v3 models
)
cohere_embedding = cohere_response["data"][0]["embedding"]
return {"openai": openai_embedding, "cohere": cohere_embedding}
def setup_qdrant_collection():
"""Create or recreate the vector collection."""
# Delete if exists
try:
qdrant_client.delete_collection(COLLECTION_NAME)
except Exception:
pass
# Create collection with two vector types
qdrant_client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config={
"openai": models.VectorParams(
size=OPENAI_EMBEDDING_DIM, distance=models.Distance.COSINE
),
"cohere": models.VectorParams(
size=COHERE_EMBEDDING_DIM, distance=models.Distance.COSINE
),
},
)
def upsert_chunks(chunks: List[Dict]):
"""Upsert document chunks to the vector store."""
for i, chunk in enumerate(chunks):
# Get both embeddings using LiteLLM
embeddings = get_embeddings(chunk["content"])
# Create payload
payload = {**chunk["metadata"], "content": chunk["content"], "chunk_index": i}
# Upsert to Qdrant
qdrant_client.upsert(
collection_name=COLLECTION_NAME,
points=[
models.PointStruct(
id=f"{chunk['doc_hash']}",
payload=payload,
vector=embeddings, # Contains both 'openai' and 'cohere' embeddings
)
],
)
def main():
# Get environment variables
docs_path = os.getenv("DOCS_PATH")
docs_base_url = os.getenv("DOCS_BASE_URL")
if not docs_path or not docs_base_url:
raise ValueError("DOCS_PATH and DOCS_BASE_URL must be set in .env file")
# Create fresh collection
setup_qdrant_collection()
# Process all documents
all_docs = get_all_docs(docs_path)
for doc_path in tqdm.tqdm(all_docs):
print(f"Processing {doc_path}")
chunks = process_doc(doc_path, docs_path, docs_base_url)
upsert_chunks(chunks)
This script performs the following steps:
- Loads documentation files: Reads all
.mdxfiles from the documentation directory. - Processes documents: Chunks the text, adds metadata (e.g. the url where the page where to be found)..
- Generates embeddings: Generate embeddings for each chunk using both OpenAI and Cohere models. We use both because we would like to compare them in the playground.
- Stores embeddings in Qdrant: Upserts the embeddings into a Qdrant collection for later retrieval. We use named vectors to save multiple embeddings for the same document.
To run the ingestion pipeline, you need first to create a collection in Qdrant and then set the following environment variables:
QDRANT_URL: The URL of your Qdrant instance.QDRANT_API_KEY: The API key for your Qdrant instance.DOCS_PATH: The folder containing the documentation (in our case it's underagenta/docs/docs).DOCS_BASE_URL: The base URL where the documentation can be found (in our case it'shttps://docs.agenta.ai).
The complete ingestion script with a setup readme is available in Github.
The query RAG workflow
Now that we have ingested the documentation into the Qdrant vector database, let's create the query logic for our assistant. Parts related to the Agenta integrations are highlighted.
import agenta as ag
from pydantic import BaseModel, Field
from typing import Annotated
from agenta.sdk.assets import supported_llm_models
system_prompt = """
You are a helpful assistant that answers questions based on the documentation.
"""
user_prompt = """
Here is the query: {query}
Here is the context: {context}
"""
ag.init()
litellm.callbacks = [ag.callbacks.litellm_handler()]
# Initialize Qdrant client
qdrant_client = QdrantClient(
url=os.getenv("QDRANT_URL"), api_key=os.getenv("QDRANT_API_KEY")
)
# We define here the configuration that will be used by the playground
class Config(BaseModel):
system_prompt: str = Field(default=system_prompt)
user_prompt: str = Field(default=user_prompt)
embedding_model: Annotated[str, ag.MultipleChoice(["openai", "cohere"])] = Field(
default="openai"
)
llm_model: Annotated[str, ag.MultipleChoice(choices=supported_llm_models)] = Field(
default="gpt-3.5-turbo"
)
top_k: int = Field(default=10, ge=1, le=25)
rerank_top_k: int = Field(default=3, ge=1, le=10)
use_rerank: bool = Field(default=True)
def get_embeddings(text: str, model: str) -> Dict[str, List[float]]:
"""Get embeddings using both OpenAI and Cohere models via LiteLLM."""
if model == "openai":
return embedding(model="text-embedding-ada-002", input=[text])["data"][0]["embedding"]
elif model == "cohere":
return embedding(
model="cohere/embed-english-v3.0",
input=[text],
input_type="search_query", # Use search_query for queries
)["data"][0]["embedding"]
raise ValueError(f"Unknown model: {model}")
@ag.instrument()
def search_docs(
query: str, collection_name: str = os.getenv("COLLECTION_NAME", "docs_collection")
) -> List[Dict]:
"""
Search the documentation using embeddings.
Args:
query: The search query
collection_name: Name of the Qdrant collection to search
Returns:
List of dictionaries containing matched documents and their metadata
"""
# Get embeddings for the query
config = ag.ConfigManager.get_from_route(Config)
# Search using embeddings
results = qdrant_client.query_points(
collection_name=collection_name,
query=get_embeddings(query, config.embedding_model),
using=config.embedding_model,
limit=config.top_k,
)
# Format results
formatted_results = []
for result in results.points:
formatted_result = {
"content": result.payload["content"],
"metadata": {
"title": result.payload["title"],
"url": result.payload["url"],
"score": result.score,
},
}
formatted_results.append(formatted_result)
return formatted_results
@ag.instrument()
def llm(query: str, results: List[Dict]):
config = ag.ConfigManager.get_from_route(Config)
context = []
for i, result in enumerate(results, 1):
score = result["metadata"].get("rerank_score", result["metadata"]["score"])
item = f"Result {i} (Score: {score:.3f})\n"
item += f"Title: {result['metadata']['title']}\n"
item += f"URL: {result['metadata']['url']}\n"
item += f"Content: {result['content']}\n"
item += "-" * 80 + "\n"
context.append(item)
# We store the context in the trace so that it can be used for evaluation
ag.tracing.store_internals({"context": context})
response = completion(
model=config.llm_model,
messages=[
{"role": "system", "content": config.system_prompt},
{
"role": "user",
"content": config.user_prompt.format(
query=query, context="".join(context)
),
},
],
)
return response.choices[0].message.content
@ag.instrument()
def rerank_results(query: str, results: List[Dict]) -> List[Dict]:
"""Rerank the search results using Cohere's reranker."""
config = ag.ConfigManager.get_from_route(Config)
# Format documents for reranking
documents = [result["content"] for result in results]
# Perform reranking
reranked = rerank(
model="cohere/rerank-english-v3.0",
query=query,
documents=documents,
top_n=config.rerank_top_k,
)
# Reorder the original results based on reranking
reranked_results = []
for item in reranked.results:
# The rerank function returns dictionaries with 'document' and 'index' keys
reranked_results.append(results[item["index"]])
# Add rerank score to metadata
reranked_results[-1]["metadata"]["rerank_score"] = item["relevance_score"]
return reranked_results
# We define here the route that will be used by the playground
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate(query: str):
config = ag.ConfigManager.get_from_route(Config)
results = search_docs(query)
if config.use_rerank:
reranked_results = rerank_results(query, results)
return llm(query, reranked_results)
else:
return llm(query, results)
Our system uses a standard RAG workflow consisting of three main steps:
- Searching the documentation: Uses the query to retrieve relevant documents from Qdrant.
- Optionally reranking results: Improves the relevance of results using Cohere's reranker.
- Generating the answer: Constructs a prompt with the query and context, then calls the LLM to generate the final answer.
To integrate this script with Agenta, we need to make two main adjustments:
- Instrumentation: Use
@ag.instrument()decorator to trace inputs, outputs, and internal variables. - Integration with the Playground: Use
ag.route()to define a route and later create a service that will be used to test the app in the playground.
We'll discuss these in more detail in the next sections.
Instrumentation
Tracing captures the inputs and outputs of all functions and LLM calls in our app. This helps us debug multi-step workflows (for example, determining whether an incorrect response stems from the LLM call or from incorrect context) and monitor usage over time.
@ag.instrument()
def generate(query: str):
...
Instrumenting code in Agenta is straightforward. The @ag.instrument() decorator lets you capture function inputs and outputs to create a trace tree.
Agenta also provides auto-instrumentation for most frameworks and libraries. Since we're using litellm, we'll use Agenta's callback function to automatically instrument its calls.
For RAG evaluation of our applications, we need to evaluate the relevancy of retrieved context for each query. Since context isn't part of any function's input or output, we'll add it manually to a span using ag.tracing.store_internals({"context": context}), which stores internal variables in the ongoing span.
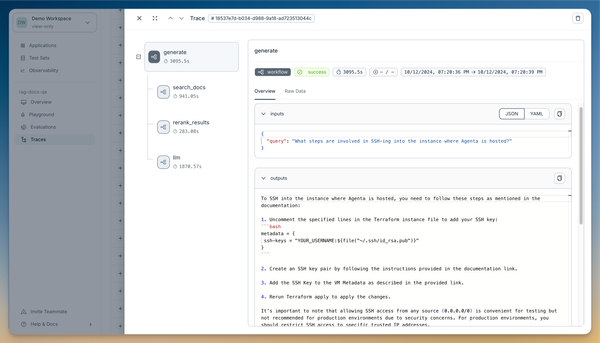
Playground integration
Agenta provides a custom playground for testing application parameters. Here, we can experiment with different embeddings, top_k values, and LLM models.
Using the Agenta SDK, we'll define a configuration schema for our application and create an endpoint to enable playground communication. Then, we'll deploy the application to Agenta Cloud using the Agenta CLI for testing. Agenta handles all infrastructure work needed to create our application service.
Defining the configuration
Let's define the configuration schema for our application. This schema will determine what elements appear in the playground UI and what parameters we can experiment with.
Our configuration includes:
- System prompt: The system prompt template
- User prompt: The user prompt template
- Embedding model: Choice between OpenAI and Cohere
- LLM model: Selection from supported language models
- Top_k value: Number of document chunks to retrieve from the vector database
- Use rerank: Toggle for Cohere's reranking feature
- Rerank top_k value: Number of chunks the reranker should return (used for both reordering and filtering)
from pydantic import BaseModel, Field
from typing import Annotated
import agenta as ag
from agenta.sdk.assets import supported_llm_models
class Config(BaseModel):
system_prompt: str = Field(default=system_prompt)
user_prompt: str = Field(default=user_prompt)
embedding_model: Annotated[str, ag.MultipleChoice(["openai", "cohere"])] = Field(
default="openai"
)
llm_model: Annotated[str, ag.MultipleChoice(choices=supported_llm_models)] = Field(
default="gpt-3.5-turbo"
)
top_k: int = Field(default=10, ge=1, le=25)
rerank_top_k: int = Field(default=3, ge=1, le=10)
use_rerank: bool = Field(default=True)
We implement this using a standard Config Pydantic class that inherits from BaseModel. The fields use simple types (str or int). Agenta requires each field to have a default value. For multiple-choice fields, we use Annotated[str, ag.MultipleChoice(choices=["choice1", "choice2"])] to specify the available options.
supported_llm_models is a helper variable provided by Agenta that contains the list available in LiteLLM.
Creating the endpoint and using the configuration
Next, we'll create an endpoint to enable communication between the playground and our application.
@ag.route("/", config_schema=Config)
def generate(query: str):
config = ag.ConfigManager.get_from_route(Config)
...
The decorator @ag.route("/", config_schema=Config) registers the generate function as an endpoint and uses the Config class to define the configuration schema. This creates a POST /playground/run endpoint that accepts the configuration as a parameter and runs the workflow. The playground uses this endpoint to interact with the service.
To get the configuration from the request, we use ag.ConfigManager.get_from_route(Config), which returns a Config object containing the values provided by the playground.
We can use these configuration values throughout our workflow. For instance, we can use config.use_rerank in the generate function to control the reranking feature.
Note that ag.ConfigManager.get_from_route(Config) is accessible in any function called within the generate function's execution path, as the configuration is preserved in the context.
Deploying the application to Agenta
Now that we have everything ready to deploy our application to Agenta, let's proceed. First, add the requirements.txt file to the same folder as your project files and populate the .env file with your environment variables. Then run these commands:
agenta init
agenta variant serve query.py
The first command creates a new application in Agenta, while the second command serves the application and creates a playground for testing.
Under the hood, agenta variant serve creates a docker image of your application and sets up a service for it in Agenta Cloud.
Once complete, you can access the playground and begin testing your application.
Evaluating the assistant
To ensure our assistant provides accurate and relevant answers, we'll use evaluators to assess its performance. We will create two evaluators:
- RAG Relevancy Evaluator: Measures how relevant the assistant's answers are with respect to the retrieved context.
- LLM-as-a-Judge Evaluator: Rates the quality of the assistant's responses.
For the first, we use the RAG Relevancy evaluator as described in Agenta's evaluation documentation.
Configuration:
- Question key:
trace.generate.inputs.query - Answer key:
trace.generate.outputs - Contexts key:
trace.generate.llm.internals.context
This evaluator measures how relevant the assistant's answers are with respect to the retrieved context. Note that we use trace.generate.llm.internals.context, which we previously stored in the span, to get the context from the trace.
You can use the evaluator playground to configure the evaluator and identify the correct trace data to use in your configuration (see image below).
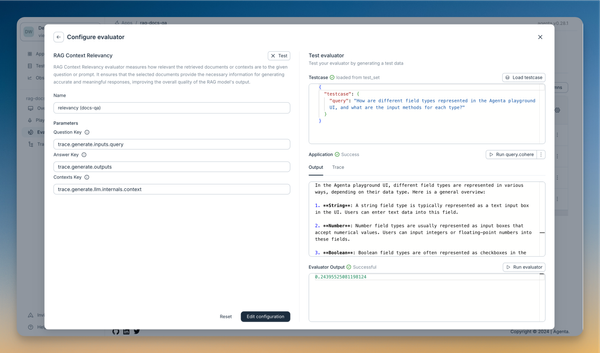
We set and test an LLM-as-a-Judge evaluator to rate the quality of the assistant's responses the same way. More details on setting up LLM-as-a-Judge evaluators can be found here.
Deploying the assistant
After iterating through various prompts and parameters and evaluating their performance, we can deploy our satisfied solution as an API endpoint using Agenta.
Simply click the Deploy button in the playground to accomplish this.
Agenta provides us with two endpoints to interact with our deployed application:
- The first allows us to directly invoke the deployed application with the production configuration.
- The second allows us to fetch the deployed configuration as a JSON and use it in our self-deployed application.
Conclusion
In this tutorial, we built a documentation Q&A system using RAG, but more importantly, we created a comprehensive LLMOps workflow that includes:
- A playground for testing different embeddings, prompts, and retrieval parameters in real time
- Observability tools for debugging multi-step RAG workflows and monitoring production performance
- Evaluation pipelines for assessing both RAG relevancy and response quality
- Deployment capabilities for smoothly transitioning from experimentation to production
This workflow shows how to evolve beyond a basic RAG implementation to build a production-ready system with robust testing, monitoring, and iteration capabilities.